The bug forces the software to apdate ,evolve into something new because of it,
work around it or work through it .
No matter what ,it changes ,it become something new,the next version,the inevitable upgrade.
引言
来爬个虫,本期我们的目标是爬取网易云音乐歌曲的评论信息,
这些评论信息对我们有什么用呢?
- 首先,我们可以知道每首歌的评论数,以此来模糊判断歌曲的受欢迎程度;
- 其次,我们可以知道歌曲的评论信息,热评,里面你会发现大家各个都是人才;
- 最后,我们可以知道用户的评论行为,如果你进一步抓取用户ID,你可以知道ta的听歌、歌单、个人信息等。

免责声明
为了避免网易云音乐给我寄送律师函警告,首先当然是要来一个免责声明。本博客代码内容参考了music163crawler的代码,如有侵犯网易云音乐公司以及用户的权利,请联系本人进行及时删除。
本帖仅供技术探讨和交流,请不要用做商业和盈利用途。顺便说一句,我的手机里只有网易云音乐这款APP,希望网易云音乐越来越好!
爬虫逻辑
古人云:知己知彼,百战百胜。
尼古拉斯·本拉钦云:来爬个虫,先看网页!
第①步,先打开,网页版的网易云音乐
我们的目标是爬取网易云音乐所有歌曲下面的热门评论和最新评论(假设就爬20条,或者全部,你开心就好!)。
那么我们首先需要了解网易云音乐的架构,根据这个架构确定爬虫的逻辑。
URL规律
我们知道,当我们要大规模爬取一个网站上的信息的时候,我们首要确定URL变化的规律,才能够用循环语句遍历所有的网页。
以李荣浩的《年少有为》为例,网址为https://music.163.com/#/song?id=1293886117 ,不难发现,每首歌曲的网页网址为https://music.163.com/#/song?id= +歌曲ID,这里的歌曲ID,就类似于每个人的身份证号一样。
那么我们如何知道所有全部歌曲的ID呢?
爬虫逻辑
凡你在网页上看到的内容
你都能通过爬虫抓取下来
爬虫策略:每一个歌手,有很多张专辑;每一张专辑,有很多首歌;每一首歌,下面有很多条评论。
获取歌手ID
在歌手列表界面,网易云音乐歌手列表,我们可以发现,每一个歌手都在一个对应的组别下面,每一个组别,按照字母顺序A~Z以及其他,分门别类的安放。例如 , 李荣浩,在华语男歌手,字母L里面。
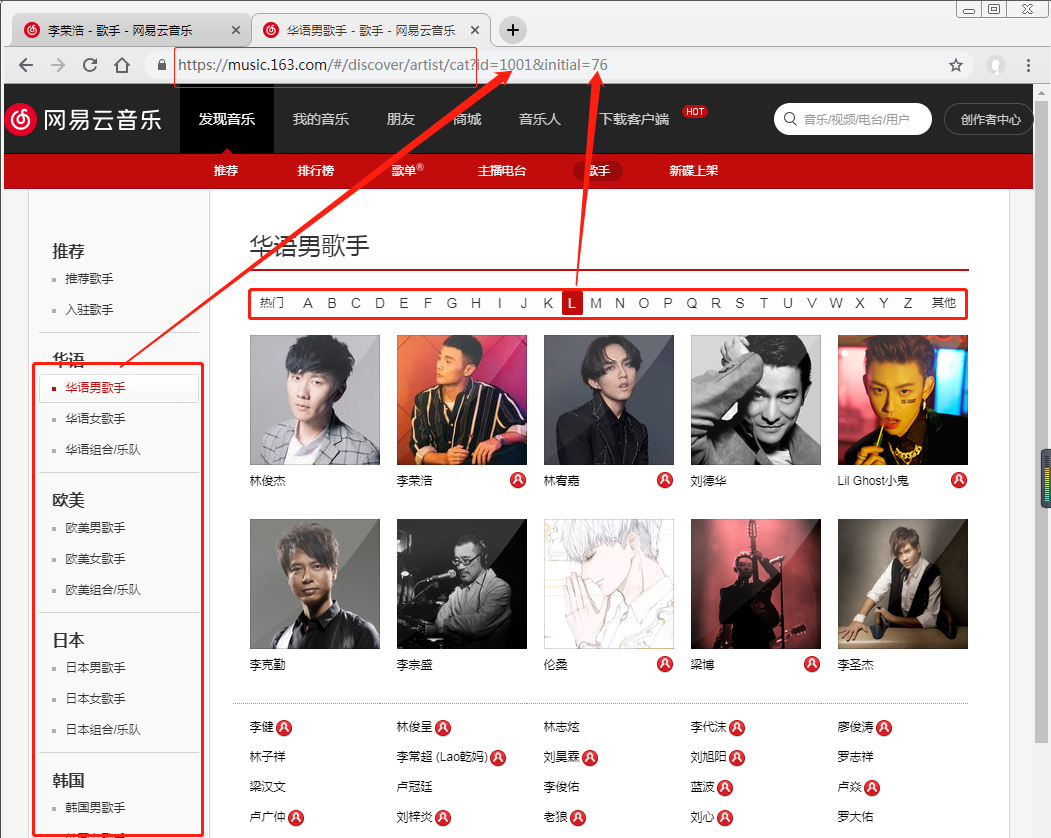
在这个歌手列表的界面,我们需要的信息就在网页源代码里鼠标移动到任一歌手下面---鼠标右键--检查,我们可以爬取到 全部歌手 这一数据!
看以上图片,我们知道歌手列表的URL循环有三部分构成:
基础URL:保持不变的部分。https://music.163.com/#/discover/artist/cat?;组别:第一个参数id = [1001,1002,1003,2001,2002,2003,···,];字母顺序:第二个参数initial = [65,66,67,...,85,87,88,89,90,0].
我们获得了包括李荣浩在内的所有歌手的ID,李荣浩在网易云音乐的ID为4292。
获取专辑ID
在歌手个人主页,我们可以抓取歌手发布的专辑的信息专辑ID+专辑名称等;
个人主页中所有专辑列表的URL为https://music.163.com/#/artist/album?id=+我们上一步得到的每个歌手的ID,例如李荣浩歌手ID为4292,那么他的专辑列表为,https://music.163.com/#/artist/album?id=4292
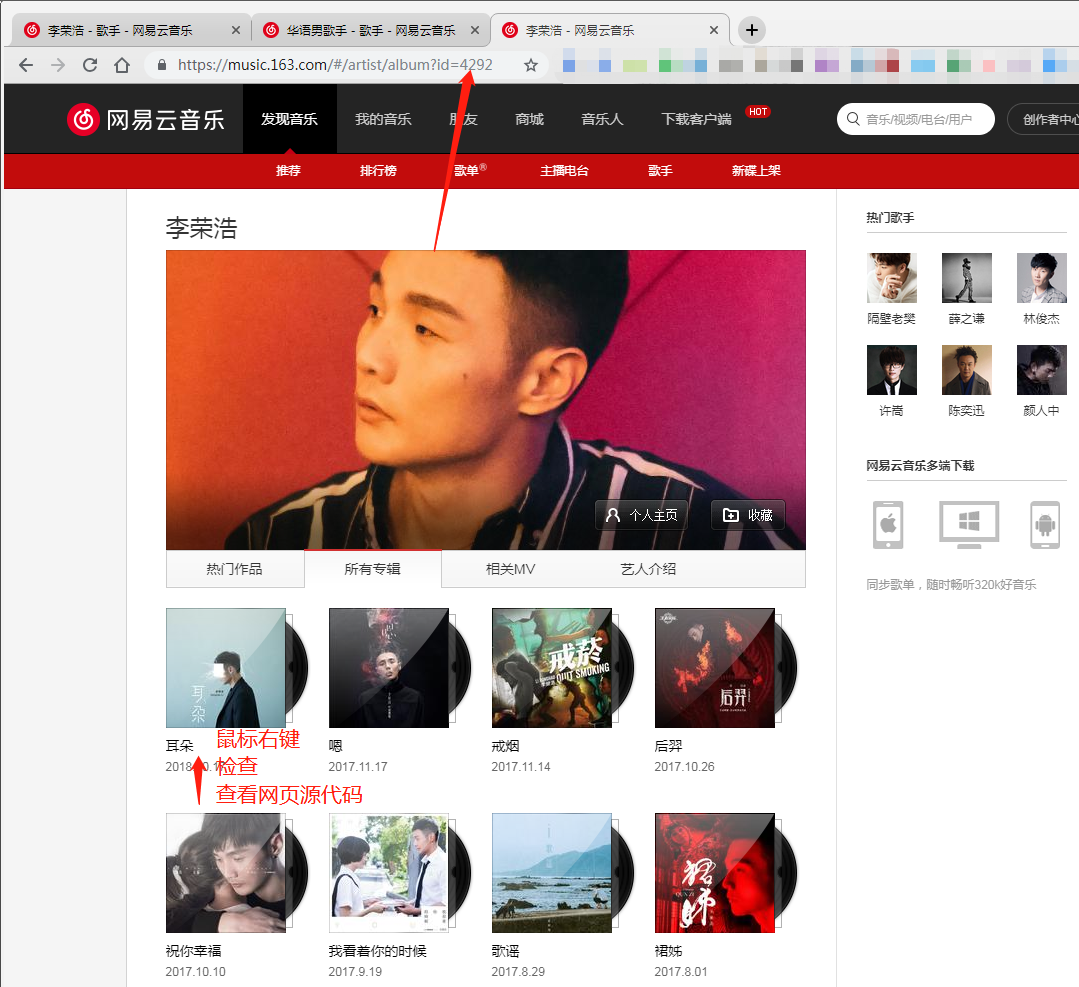
在这一个界面下,我们需要的信息就在网页源代码里鼠标移动到任一歌手下面---鼠标右键--检查,我们可以爬取到 某一位歌手的全部专辑 这一数据!
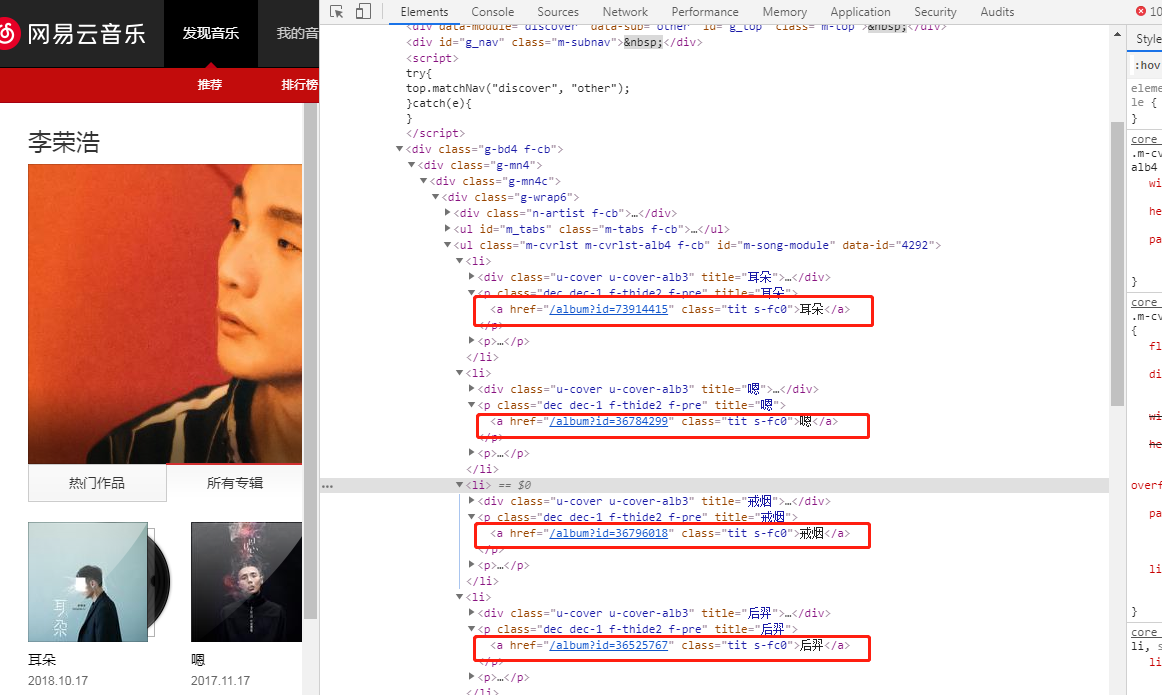
这里我们发现,歌手有不止一页的专辑,就涉及到翻页的问题,怎么办呢?这里有一个小技巧。
以李荣浩为例,他
第一页专辑的URL为:https://music.163.com/#/artist/album?id=4292
第二页的专辑URL为: https://music.163.com/#/artist/album?id=4292&limit=12&offset=12
我们看到第二页比第一页多了一些东西,limit表示每一页限制显示多少个专辑,offset为下一页相比于第一页的偏移量(也就是前面有多少专辑).一种简单粗暴的方法就是,直接将limit设置成200,使所有专辑显示在一页里面。
获取歌曲ID
得到专辑ID后,我们就可以来到专辑的页面了。
某一位歌手某一张专辑的URL为https://music.163.com/#/album?id=+我们上一步得到的每张专辑的ID,例如李荣浩的专辑耳朵ID为73914415,那么这张专辑歌曲列表的URL为:https://music.163.com/#/album?id=73914415。
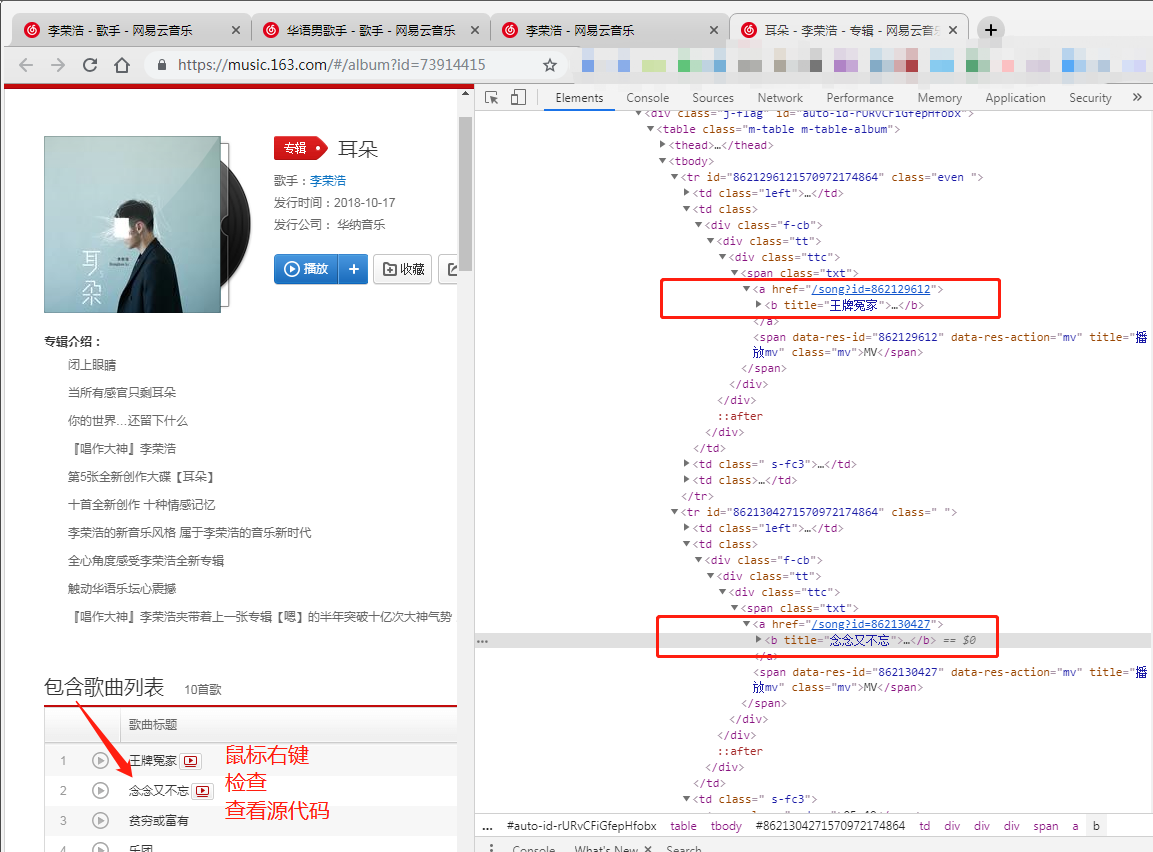
在这一个界面下,我们需要的信息就在网页源代码里鼠标移动到任一歌手下面---鼠标右键--检查,我们可以爬取到 某一张专辑全部歌曲ID 这一数据!
获取歌曲评论
再通过前面几步,我们就得到了全部歌曲的ID了,然后我们就可以结合具体的一些代码,爬取每首歌下面的评论啦。
代码解析
完整代码参见爬取网易云音乐的评论,代码解析如下:
爬虫三步走:
- 抓取数据;
- 解析数据;
- 保存数据。
导入包
导入程序所需要的第三方库,采用requests来抓取网页源代码,BeautifulSoup来解析数据,Pandas来
import requests
from bs4 import BeautifulSoup
import pandas as pd
设置请求头
为了避免被网站识别成恶意程序或者爬虫,我们往往需要多重伪装,最简单的可能就是设置请求头信息,设置休眠时间,更高阶的,代理IP等。
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'zh-CN,zh;q=0.8,en;q=0.6',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'Cookie': '_ntes_nnid=7eced19b27ffae35dad3f8f2bf5885cd,1476521011210; _ntes_nuid=7eced19b27ffae35dad3f8f2bf5885cd; usertrack=c+5+hlgB7TgnsAmACnXtAg==; Province=025; City=025; NTES_PASSPORT=6n9ihXhbWKPi8yAqG.i2kETSCRa.ug06Txh8EMrrRsliVQXFV_orx5HffqhQjuGHkNQrLOIRLLotGohL9s10wcYSPiQfI2wiPacKlJ3nYAXgM; P_INFO=hourui93@163.com|1476523293|1|study|11&12|jis&1476511733&mail163#jis&320100#10#0#0|151889&0|g37_client_check&mailsettings&mail163&study&blog|hourui93@163.com; NTES_SESS=Fa2uk.YZsGoj59AgD6tRjTXGaJ8_1_4YvGfXUkS7C1NwtMe.tG1Vzr255TXM6yj2mKqTZzqFtoEKQrgewi9ZK60ylIqq5puaG6QIaNQ7EK5MTcRgHLOhqttDHfaI_vsBzB4bibfamzx1.fhlpqZh_FcnXUYQFw5F5KIBUmGJg7xdasvGf_EgfICWV; S_INFO=1476597594|1|0&80##|hourui93; NETEASE_AUTH_SOURCE=space; NETEASE_AUTH_USERNAME=hourui93; _ga=GA1.2.1405085820.1476521280; JSESSIONID-WYYY=cbd082d2ce2cffbcd5c085d8bf565a95aee3173ddbbb00bfa270950f93f1d8bb4cb55a56a4049fa8c828373f630c78f4a43d6c3d252c4c44f44b098a9434a7d8fc110670a6e1e9af992c78092936b1e19351435ecff76a181993780035547fa5241a5afb96e8c665182d0d5b911663281967d675ff2658015887a94b3ee1575fa1956a5a%3A1476607977016; _iuqxldmzr_=25; __utma=94650624.1038096298.1476521011.1476595468.1476606177.8; __utmb=94650624.20.10.1476606177; __utmc=94650624; __utmz=94650624.1476521011.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none)',
'DNT': '1',
'Host': 'music.163.com',
'Pragma': 'no-cache',
'Referer': 'http://music.163.com/',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36'
}
请求头信息,可以通过右键检查,查看network属性,主站网址下面的headers信息。
爬取歌手ID
def save_artist(group_id, initial, hot_artist_dic, artisti_dic):
params = {'id': group_id, 'initial': initial}
r = requests.get('http://music.163.com/discover/artist/cat', params=params)
# 网页解析
soup = BeautifulSoup(r.content.decode(), 'html.parser')
body = soup.body
hot_artists = body.find_all('a', attrs={'class': 'msk'})
artists = body.find_all('a', attrs={'class': 'nm nm-icn f-thide s-fc0'})
for artist in hot_artists:
artist_id = artist['href'].replace('/artist?id=', '').strip()
artist_name = artist['title'].replace('的音乐', '')
try:
hot_artist_dic[artist_id] = artist_name
except Exception as e:
# 打印错误日志
print(e)
for artist in artists:
artist_id = artist['href'].replace('/artist?id=', '').strip()
artist_name = artist['title'].replace('的音乐', '')
try:
artist_dic[artist_id] = artist_name
except Exception as e:
# 打印错误日志
print(e)
#return artist_dic, hot_artist_dic
定义函数能够帮助我们快速、方便、集成地调用。集合循环语句,我们能将所有的歌手ID爬取下来。
gg= #group_id
artist_dic = {}
hot_artist_dic = {}
initial = list(range(65,91))
initial.append(0) #namelist
for i in initial:
print(i)
save_artist(gg, i, hot_artist_dic, artist_dic )
爬取专辑ID
结合上一步得到的歌手ID,写一个循环语句,调用下面的函数,就能爬取每个歌手下面的专辑。
def save_albums(artist_id, albume_dic):
params = {'id': artist_id, 'limit': '200'}
# 获取歌手个人主页
r = requests.get('http://music.163.com/artist/album', headers=headers, params=params)
# 网页解析
soup = BeautifulSoup(r.content.decode(), 'html.parser')
body = soup.body
albums = body.find_all('a', attrs={'class': 'tit s-fc0'}) # 获取所有专辑
for album in albums:
albume_id = album['href'].replace('/album?id=', '')
albume_dic[albume_id] = artist_id
抓取歌曲ID
def save_music(album_id, music_dic):
params = {'id': album_id}
# 获取专辑对应的页面
r = requests.get('http://music.163.com/album', headers=headers, params=params)
# 网页解析
soup = BeautifulSoup(r.content.decode(), 'html.parser')
body = soup.body
musics = body.find('ul', attrs={'class': 'f-hide'}).find_all('li') # 获取专辑的所有音乐
for music in musics:
music = music.find('a')
music_id = music['href'].replace('/song?id=', '')
music_name = music.getText()
music_dic[music_id] = [music_name, album_id]
这里还需要注意及时的保存数据,建议转换成Dataframe的格式,存储成csv。通过这一步,我们保存了歌曲的ID
抓取歌曲评论
接下来,是最为激动人心的时刻了,抓取歌曲评论,但我们会发现,我们再利用上面的逻辑,requests获取不到数据,这是因为评论数据对于网易云音乐来说可以说就是生命,它设置了加密的方式、反爬的措施。
但是道高一尺,魔高一丈。在许多大佬的帮助下,这里我们有两种解决方法:
- 通过评论的API接口爬取:
http://music.163.com/api/v1/resource/comments/R_SO_4_SONG_ID?limit=20&offset=0 - 通过解密方法。这个也是有点厉害,反正我也不会,也就是copy-paste-copy-paste大佬的代码,跑一跑,发现实在是厉害~
代码详见GIthub主页。 爬取网易云音乐的评论,整理不易,尊重他人劳动成果,注明出处。
总结
爬虫的快感在于,这似乎是你和网站程序设计者之间的一场较量,当你得到了你想要的数据的时候,不可避免地会达到颅内高潮!
一个完整的可以运行的程序,需要你不断的debug,debug,debug,直至代码可以运行,至少不报错。
当然,这还只是万里长征的第一步,接下来,如何从数据中窥见人类行为的秘密,才是最考验数据科学家素养的地方~~~